Building self-healing, observable systems with AWS Step Functions
Modern highly-distributed application architectures solve real problems, but they bring with them novel challenges. Knowing what is…

Modern highly-distributed application architectures solve real problems, but they bring with them novel challenges. Knowing what is happening in production and which part of the system needs fixing is non-trivial and makes understanding outages challenging for the most informed experts.
AWS Step Functions is targeted at coordinating the tangle of microservices and serverless functions that make up the cutting edge backend architectures. I’ve been using it at scale for over a year now and have been impressed with the confidence and deep understanding it gives both developers and the on-call engineers who keep it running in production.
Let’s dive into a few techniques for using it more successfully.
Workflows are everywhere and you don’t even know it
The core concept of Step Functions is a single execution of a configured workflow (state machine). Though you may not think of it, many applications are built by assembling a series of tasks together, perhaps passing some context between them. These are workflows!
Step Functions’s core contract involves the developer defining the steps of a workflow and the code to run each step. Then whenever this workflow is executed, AWS manages its state and calls the right step at the right time.
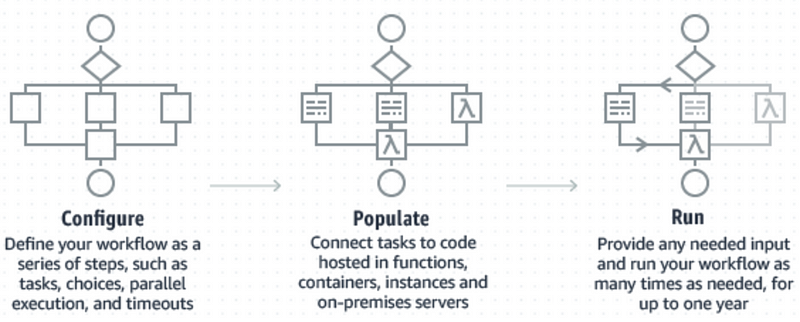
This decomposition lets the developer focus on writing small tasks that do one thing well (where have I heard that before?) and compose them together into production workflows that accomplish business goals. And, in grand tradition, AWS handles the undifferentiated heavy lifting of managing concurrent executions, storing a small in-execution JSON data blob, and knowing which task to invoke when.
Resilient right out of the box
In large production systems, it’s easy to accidentally implement important business processes like Rube Goldberg machines: if any part of the system goes wrong the total result won’t work properly and figuring out what broke after the fact is a total mystery.
One of the immediate benefits of Step Functions is its resiliency and auditability.
Resiliency comes from the first-class error handling in the workflow definition language. You can define retries, exponential backoff, state transitions, and more all in your workflow’s JSON definition. Best of all, this behavior is defined entirely outside the code implementing each step in your workflow — this lets your main code focus on behavior and compose that with your workflow’s retry configuration. Great separation!
But even in the most well-defined workflow, you’ll inevitably have workflows that fail for reasons you don’t immediately understand. Luckily Step Functions provides a build in audit log of every execution’s progress through your workflow. This includes inputs, outputs, errors, timings, retries, and timeouts for the whole execution. This kind of detailed debugging info makes noticing issues and pinning them down to individual workflow steps trivially easy with no additional effort on your part.
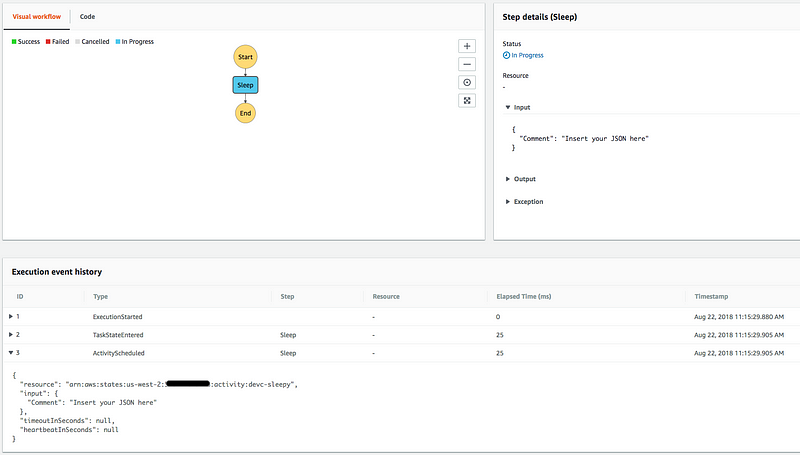
You can see a nice visual of all this in the AWS console, but the same data is available via the GetExecutionHistory API call.
Was that error your fault or mine?
The only problem left is creating a workflow design that clearly communicates all this great context to your oncall engineers so they can rapidly tell whether workflows are failing correctly (bad input maybe?) or due to a bug (your datastore is on the fritz again).
The most successful way I’ve seen this done is by separating workflows into three conceptual kinds of terminal states — success, known failure modes, and unknown failure modes. In service terms, these correspond to 2xx, 4xx, and 5xx HTTP status codes.
Applying these ideas to a workflow for storing user information might look something like this:
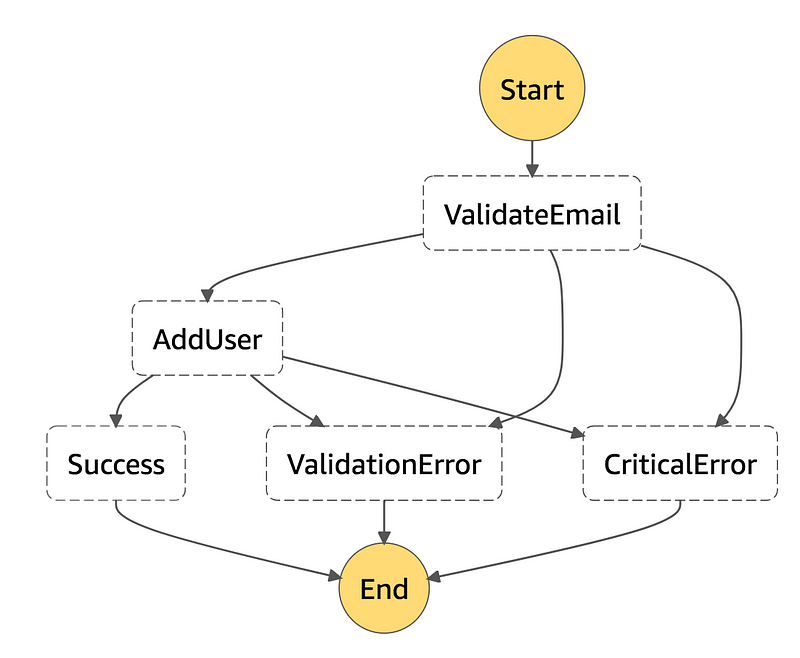
Now if we notice input issues (e.g. someone entered garbage for the email address), we transition to the ValidationError state and end the workflow. On the other hand if we get to AddUser and our datastore is unavailable, we might end up in the CriticalError state.
The benefit for this effort is which terminal state you end up in tells you something about the health of the workflow:
- The “success” end states signal the workflow executed cleanly
- The “validation error” end state may not inherently signal problems (sometimes input is invalid!), but the rate at which they’re executed should be monitored. Often you can set up baseline frequency for these cases and monitor exceeding a threshold.
- The “critical error” is a problem! Any executions that end up in this state either indicate a significant dependency failing entirely or the presence of a novel bug in your workflow.
If we look at the Step Functions workflow DSL for this, you can see how these transitions look in code:"States": {
"ValidateEmail": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:1234:function:myfunc",
"Catch": [
{
"ErrorEquals": ["ValidationError, SerializationError"],
"Next": "ValidationError",
"ResultPath": "$.exception_details"
},
{
"ErrorEquals": ["States.ALL"],
"Next": "CriticalError",
"ResultPath": "$.exception_details"
}
],
"Next": "AddUser"
},
..
We create a custom list of errors we consider “validation errors” and catch those and transition to the ValidationError state, and then catch any other errors and head to CriticalError. If we want, a separate Retry clause can let us retry on some errors while immediately transitioning for others. Finally the ResultPath ensures that we’re capturing the exception context and handing it along to the next state without clobbering the rest of the input.
This pattern of activities gives you crystal clear signals to focus alerting on (too many workflows ending in either kind of failure mode) so you can notice production problems promptly and diagnose them accurately. As a bonus, the unknown failure mode state acts as a very fast feedback loop for any kinds of behaviors you’ve forgotten to build into your main workflow. Simply notice a new type of unknown failure mode, triage how to either eliminate it or make it a known failure mode, rinse and repeat.
Leaving the world a little cleaner than you found it
There’s just one hitch with this plan: some failure modes require cleanup. In a distributed system, we can’t rely on enormous database transactions to keep systems consistent…we have to implement that ourselves.
The most general version of this is often referred to as the Saga Pattern. That pattern holds that for every side effect, you need a compensating “undo” equivalent side effect. You can see how this general case might look in Yan Cui’s Medium post about implementing Saga Patterns with Step Functions.
But in most cases you can simplify this approach and make relatively few steps which undo the most critical side effects your workflow performs.
Whether you go for the minimal or large-scale version of these undo steps, the goal is for your workflow to clean up after itself. Ideally when you any terminal state (even “unknown failure mode”!), your data is in a consistent state and doesn’t require additional cleanup.
This consistency allows your oncall engineers to focus on understanding causes and mitigating damage, even in the worst outages, secure in the knowledge that the workflows have automatically cleaned up any bad data they created.
Iterating to stability in production
So we’ve built a production system that executes our workflow, includes retries+timeouts where we need them, has very well defined failure modes, and can give us clear feedback whenever we need to tweak our design because it isn’t robust to all possible production realities.
Using Step Functions doesn’t magically make your code stable in production, but it does allow you to easily compose your business logic with a platform that handles the resiliency and auditability for you.
If you found this interesting, follow Scott Triglia on Twitter (https://twitter.com/scott_triglia) or his blog at http://www.locallyoptimal.com/.